Resuelve problemas de estadística paso a paso con explicaciones claras. Sube una foto de tu pregunta de estadística o escríbela y obtén soluciones instantáneas y precisas. Ideal para estudiantes y profesionales que necesitan ayuda con conceptos, cálculos y análisis de datos estadísticos.
🚀 Impulsado por los mejores modelos de IA
🌍 Soporta más de 40 idiomas
💳 No se requiere tarjeta de crédito
⭐ Calificaciones de 5 estrellas
Ahorra horas de tu tiempo
Aprovecha la IA para acelerar drásticamente la creación de contenido
Nuestra herramienta impulsada por IA puede generar contenido de alta calidad y personalizado en segundos, no en horas. Aumenta tu productividad y concéntrate en lo que realmente importa.
Es fácil empezar
Texto generado por IA
ENTRADA
See attached files
SALIDA
Análisis
Se trata de un estudio descriptivo de datos continuos (tiempos de respuesta) y un análisis de correlación bivariante (temperatura vs. tiempo).
En la primera parte se construye una distribución de frecuencias agrupadas, se calculan medidas de tendencia central, dispersión y posición.
En la segunda parte se calcula el coeficiente de correlación de Pearson y el de Spearman para evaluar la relación lineal entre temperatura y tiempo de respuesta.
Solución
Distribución de frecuencias agrupada
Tamaño de la muestra: n=80
Mínimo: xmin=270, Máximo: xmax=345
Rango: R=xmax−xmin=345−270=75
Número de clases (Regla de Sturges): k=1+3.322log10(80)≈7.32≈8
Amplitud de clase: h=kR≈875≈9.4≈10
Intervalos [límite inferior, límite superior), marcas de clase, frecuencias absolutas, acumuladas y relativas:
Intervalo
xi
fi
Fi
fi/n
[270, 280)
275
10
10
0.125
[280, 290)
285
11
21
0.1375
[290, 300)
295
12
33
0.1500
[300, 310)
305
12
45
0.1500
[310, 320)
315
12
57
0.1500
[320, 330)
325
11
68
0.1375
[330, 340)
335
9
77
0.1125
[340, 350)
345
3
80
0.0375
Medidas de tendencia central (datos agrupados)
Media aritmética: xˉ=n1i=1∑kfixi=8010⋅275+11⋅285+⋯+3⋅345=306.125 s
Mediana (interpolación): Fc−1=33,fc=12,2N=40,Lc=300 Me=300+1240−33×10≈305.83 s
Moda (primer clase modal [290,300)): d1=12−11=1,d2=12−12=0,Lmo=290 Mo=290+d1+d2d110=300 s
Conclusión: existe una relación lineal positiva muy fuerte entre la temperatura ambiente y el tiempo de respuesta en intercepción radar.
ENTRADA
See attached files
SALIDA
Puedo ver la imagen con los problemas de estadística. Voy a resolver cada ejercicio paso a paso en español.
SOLUCIÓN DE PROBLEMAS DE ESTADÍSTICA
[Analysis]
Este documento contiene tres ejercicios de estadística:
Ejercicio N°1: Análisis descriptivo comparativo de precios de renta mensual entre departamentos en ciudad y suburbio. Incluye medidas de tendencia central, dispersión y visualización con histogramas.
Ejercicio N°2: Inferencia estadística - Intervalo de confianza para la varianza poblacional usando la distribución chi-cuadrado.
Ejercicio N°3: Análisis de regresión lineal simple para pronosticar demanda de combustibles basada en temperatura, incluyendo interpretación de coeficientes, bondad de ajuste y prueba de hipótesis.
[Solution]
EJERCICIO N°1: MEDIDAS DE LOCALIZACIÓN
Datos proporcionados:
Resumen
Ciudad
Suburbio
n
10
10
Media
1016.50
718.40
Var(p-1)
8949.53
8054.85
Var(n)
3755.60
3380.04
Mediana
982.50
725.00
i) ¿La media o la mediana? ¿Qué valor reportaría?
Paso 1: Análisis de la distribución
Para la Ciudad:
Media = 1016.50
Mediana = 982.50
Diferencia: 1016.50−982.50=34
Para el Suburbio:
Media = 718.40
Mediana = 725.00
Diferencia: 718.40−725.00=−6.6
Paso 2: Interpretación
En la Ciudad, la media (1016.50) es mayor que la mediana (982.50), lo que sugiere una distribución asimétrica positiva (sesgada a la derecha). Esto indica que hay algunos departamentos con precios muy altos que elevan la media.
En el Suburbio, la media (718.40) es ligeramente menor que la mediana (725.00), sugiriendo una distribución aproximadamente simétrica o ligeramente sesgada a la izquierda.
Paso 3: Decisión
Recomendacioˊn: Reportar la MEDIANA para la Ciudad y la MEDIA para el Suburbio
Justificación: La mediana es más robusta ante valores atípicos. En la ciudad, donde hay mayor variabilidad (Var = 8949.53 vs 8054.85) y posibles valores extremos, la mediana representa mejor el "precio típico". En el suburbio, con distribución más simétrica, la media es apropiada.
ii) ¿En cuál de los sitios los precios son más homogéneos?
Paso 1: Calcular medidas de dispersión relativas
Desviación estándar (muestral):
Ciudad: sC=8949.53≈94.60
Suburbio: sS=8054.85≈89.75
Coeficiente de variación (CV): CV=xˉs×100
Ciudad: CVC=1016.5094.60×100≈9.31%
Suburbio: CVS=718.4089.75×100≈12.49%
Paso 2: Interpretación
Aunque la desviación estándar absoluta es mayor en la ciudad (94.60 > 89.75), el coeficiente de variación es menor en la ciudad (9.31% < 12.49%).
Respuesta: Los precios son maˊs homogeˊneos en la CIUDAD
Justificación: El CV de la ciudad (9.31%) es menor que el del suburbio (12.49%), lo que indica menor dispersión relativa respecto a la media. La variabilidad proporcional es menor en la ciudad.
iii) Teorema de Chebyshev para el intervalo <<| \bar{x} \pm 2.5s |>>
Paso 1: Aplicar el teorema de Chebyshev
El teorema establece que para cualquier distribución, la proporción de datos dentro de k desviaciones estándar de la media es al menos:
1−k21
Paso 2: Calcular para k = 2.5
1−(2.5)21=1−6.251=1−0.16=0.84
Respuesta: Al menos el 84% de los precios se encuentran en el intervalo xˉ±2.5s
Cálculo de los intervalos:
Ciudad:
xˉ−2.5s=1016.50−2.5(94.60)=1016.50−236.50=780.00
xˉ+2.5s=1016.50+2.5(94.60)=1016.50+236.50=1253.00
Intervalo: [780.00,1253.00]
Suburbio:
xˉ−2.5s=718.40−2.5(89.75)=718.40−224.38=494.02
xˉ+2.5s=718.40+2.5(89.75)=718.40+224.38=942.78
Intervalo: [494.02,942.78]
EJERCICIO N°2: INTERVALO DE CONFIANZA PARA VARIANZA
Paso 7: Intervalo para el desvío estándar (opcional)
0.000984≈0.0314 0.005005≈0.0707
EJERCICIO N°3: REGRESIÓN LINEAL SIMPLE
Datos de la tabla de regresión:
Coeficientes
Error típico
Estadístico t
Probabilidad
Inferior 95%
Superior 95%
Intercepción
83.0739
6.5926
12.601
0
67.4849
98.663
Variable X
-1.1848
0.1258
-9.4171
0
-1.4823
-0.8873
Estadísticas de la regresión:
Coeficiente de determinación R2=0.9268
Error típico: 3.3932
Observaciones: 9
a) Ecuación de la recta de mínimos cuadrados
Paso 1: Identificar variables
y = Demanda (consumo) de combustibles para calefacción
x = Temperatura máxima (variable independiente)
Paso 2: Escribir la ecuación
La forma general es: y^=b0+b1x
Donde:
b0=83.0739 (intercepción)
b1=−1.1848 (pendiente)
Ecuación de regresión: y^=83.0739−1.1848x
Interpretación de la pendiente:
Por cada 1 grado de aumento en la temperatura máxima, la demanda de combustible para calefacción disminuye en promedio 1.1848 unidades (miles de litros, suponiendo). Esto tiene sentido lógico: a mayor temperatura, menor necesidad de calefacción.
b) ¿Presentan los datos suficiente evidencia de que las ventas están relacionadas linealmente con las temperaturas?
Paso 1: Establecer hipótesis
H0:β1=0 (no hay relacioˊn lineal) H1:β1eq0 (sıˊ hay relacioˊn lineal)
Paso 2: Identificar estadístico de prueba
De la tabla:
Estadístico t=−9.4171
Probabilidad (p-valor) = 0
Paso 3: Decisión
Comparar p-valor con α=0.05: p-valor=0<0.05=α
Conclusión:Rechazamos H0
Respuesta:SÍ, existe evidencia estadísticamente significativa al nivel del 5% de que las ventas de combustible están relacionadas linealmente con las temperaturas máximas. El valor p es prácticamente cero, lo que indica una relación muy significativa.
c) Describa la bondad de ajuste de la ecuación obtenida
Paso 1: Analizar R2 (coeficiente de determinación)
R2=0.9268
Interpretación:
El R2=0.9268 indica que el 92.68% de la variabilidad en la demanda de combustibles para calefacción es explicada por la temperatura máxima a través del modelo lineal.
Paso 2: Analizar el error típico
se=3.3932
Este es el error estándar de la estimación, que representa la desviación típica de los residuos.
Paso 3: Evaluación cualitativa
Métrica
Valor
Interpretación
R2
0.9268
Excelente bondad de ajuste
Error típico
3.3932
Bajo en relación a la escala de la variable dependiente
Estadístico t
-9.4171
Muy significativo (
Conclusión sobre bondad de ajuste:
El modelo presenta una EXCELENTE bondad de ajuste.
El R2 de 0.9268 es muy alto, indicando que el modelo explica más del 92% de la variación en las ventas.
La relación negativa entre temperatura y demanda es fuerte y estadísticamente significativa.
El modelo es apropiado para pronosticar la demanda de combustibles basándose en las temperaturas máximas.
[Answer]
Resumen de Respuestas:
Ejercicio 1:
i) Reportar la mediana (982.50) para la ciudad y la media (718.40) para el suburbio.
ii) Los precios son más homogéneos en la CIUDAD (CV = 9.31% vs 12.49%).
iii) Al menos el 84% de los precios están en xˉ±2.5s por el teorema de Chebyshev.
Ejercicio 2:
Intervalo de confianza del 90% para σ2: [0.000984,0.005005]
Para σ: [0.0314,0.0707]
Ejercicio 3:
a) Ecuación: y^=83.0739−1.1848x
b)SÍ, hay evidencia significativa (p = 0 < 0.05) de relación lineal.
c) Excelente bondad de ajuste con R2=0.9268 (92.68% de varianza explicada).
ENTRADA
See attached files
SALIDA
Análisis del Problema
Este es un problema de análisis de regresión lineal simple y correlación entre dos variables cuantitativas continuas:
Variable independiente X: Gastos en Publicidad (miles de pesetas)
Variable dependiente Y: Volumen de Ventas (millones de pesetas)
El objetivo es:
Determinar si existe relación lineal mediante el coeficiente de correlación y el diagrama de dispersión
Obtener las rectas de regresión por el método de mínimos cuadrados
Realizar predicciones de ventas para valores específicos de inversión en publicidad
Solución
Paso 1: Tabla de Datos y Cálculos Preliminares
Los datos proporcionados son:
Año
Publicidad X (miles ptas.)
Ventas Y (mill. ptas.)
X2
Y2
XY
1
16
10
256
100
160
2
32
15
1024
225
480
3
48
20
2304
400
960
4
56
22
3136
484
1232
5
64
30
4096
900
1920
6
80
32
6400
1024
2560
Total
∑X=296
∑Y=129
∑X2=17216
∑Y2=3133
**∑XY=7312
Con n=6 observaciones.
Paso 2: Cálculo de Medias
<<|
\bar{X} = \frac{\sum X}{n} = \frac{296}{6} = 49.3333 \text{ miles de pesetas}
<<|
\bar{Y} = \frac{\sum Y}{n} = \frac{129}{6} = 21.5 \text{ millones de pesetas}
Paso 3: Cálculo de Sumas de Cuadrados y Productos Cruzados
Paso 4: Coeficiente de Correlación y Determinación (Inciso a)
Coeficiente de correlación de Pearson:
<<|
r = \frac{S_{xy}}{\sqrt{S_{xx} \cdot S_{yy}}} = \frac{948}{\sqrt{2613.333 \times 359.5}} = \frac{948}{969.275} = 0.9781
Coeficiente de determinación:
<<|
R^2 = r^2 = (0.9781)^2 = 0.9566 \text{ o } 95.66\%
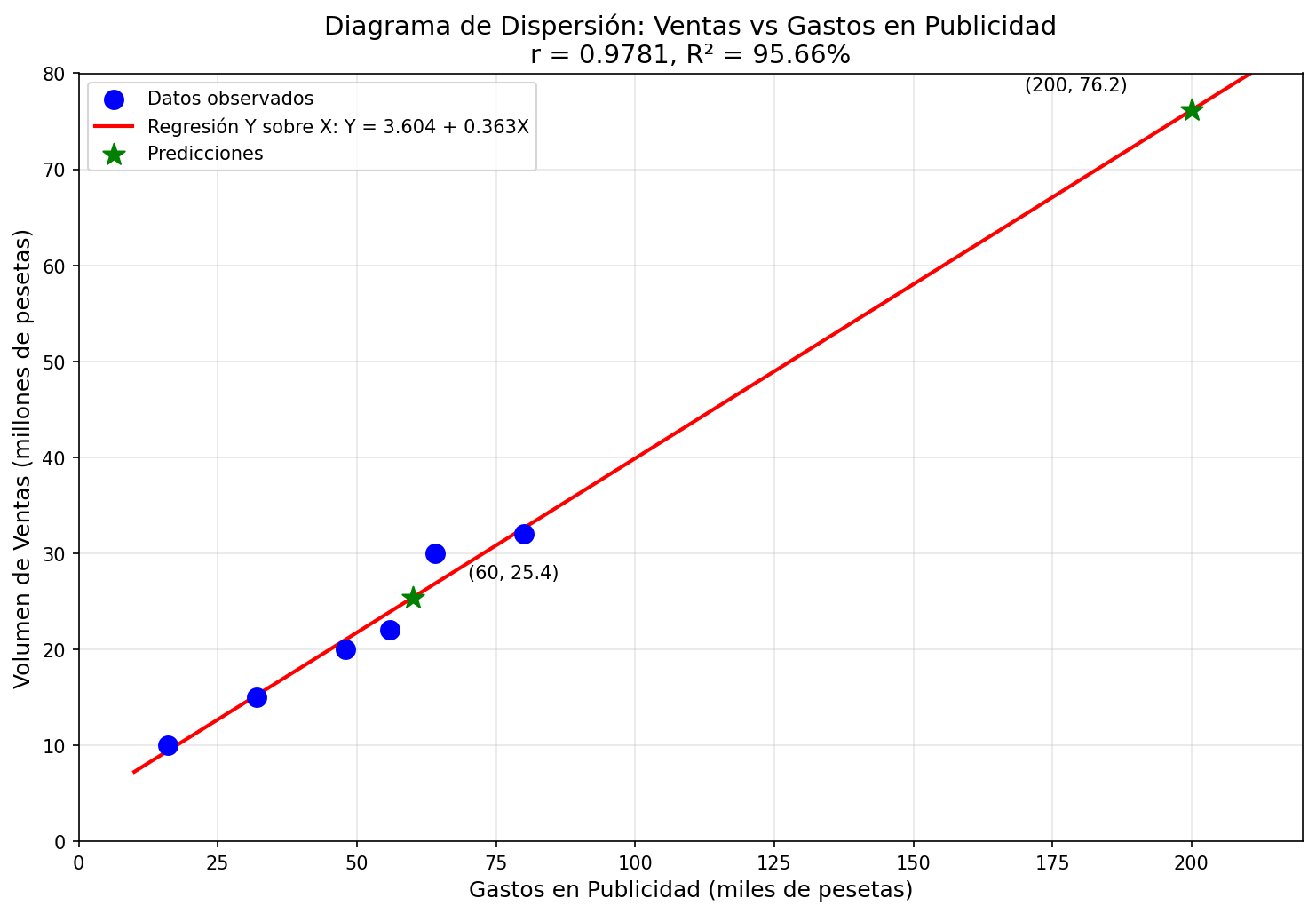
Interpretación: El coeficiente r=0.9781 indica una correlación positiva muy fuerte entre los gastos en publicidad y el volumen de ventas. El valor R2=95.66% significa que el 95.66% de la variabilidad en las ventas puede explicarse por la inversión en publicidad.
Diagrama de Dispersión:
El diagrama muestra una clara tendencia lineal ascendente, confirmando la fuerte correlación positiva calculada.
Paso 5: Rectas de Regresión Mínimo Cuadrático (Inciso b)
Recta de Regresión de Y sobre X (para predecir Ventas desde Publicidad):
La ecuación es Y=a+bX, donde:
<<|
b = \frac{S_{xy}}{S_{xx}} = \frac{948}{2613.333} = 0.3628
Por lo tanto, la recta de regresión es:
<<|
\boxed{X = -7.363 + 2.637Y}
Paso 6: Predicciones (Inciso c)
Para predecir el volumen de ventas, utilizamos la recta de regresión de Y sobre X: Y=3.6041+0.3628X
Caso 1: Gasto en publicidad de 60.000 pesetas
Como X está en miles de pesetas: X=60
<<|
Y = 3.6041 + 0.3628(60) = 3.6041 + 21.768 = 25.37 \text{ millones de pesetas}
Caso 2: Gasto en publicidad de 200.000 pesetas
Como X está en miles de pesetas: X=200
<<|
Y = 3.6041 + 0.3628(200) = 3.6041 + 72.56 = 76.16 \text{ millones de pesetas}
Advertencia importante: El valor X=200 está fuera del rango de los datos originales (16-80). Esta predicción constituye una extrapolación, por lo que debe interpretarse con cautela, ya que la relación lineal podría no mantenerse fuera del rango observado.
Respuesta Final
a) Relación lineal y coeficiente de determinación:
Sí existe una relación lineal muy fuerte positiva entre las ventas y los gastos en publicidad. El coeficiente de correlación es r=0.978 y el coeficiente de determinación es R2=95.66%, lo que indica que el 95.66% de la variación en las ventas se explica por la inversión en publicidad.
b) Rectas de regresión:
Recta de Y sobre X:Y=3.60+0.36X (Ventas en millones, Publicidad en miles)
Recta de X sobre Y:X=−7.36+2.64Y
c) Predicciones de ventas:
Para 60.000 ptas en publicidad: Y≈25.37 millones de pesetas
Para 200.000 ptas en publicidad: Y≈76.16 millones de pesetas (extrapolación)
ENTRADA
que es la estimacion?
SALIDA
Voy a resolver ambas partes: primero explicaré qué es la estimación en estadística, y luego resolveré el problema de la imagen paso a paso.
¿Qué es la Estimación?
Análisis: La estimación es uno de los conceptos fundamentales de la inferencia estadística. Consiste en utilizar información obtenida de una muestra para aproximar los valores de parámetros desconocidos de una población.
Tipos de estimación:
Estimación puntual: Proporciona un único valor numérico como aproximación del parámetro poblacional.
Ejemplo: La media muestral xˉ es un estimador puntual de la media poblacional μ.
Estimación por intervalos: Proporciona un rango de valores dentro del cual se espera que se encuentre el parámetro poblacional, con un cierto nivel de confianza.
Ejemplo: Un intervalo de confianza del 95% para μ: xˉ±zfracalpha2⋅nσ
Propiedades de los buenos estimadores:
Insesgadez: El valor esperado del estimador es igual al parámetro
Eficiencia: Varianza mínima entre todos los estimadores insesgados
Consistencia: Converge al parámetro verdadero cuando n→∞
Solución del Problema de la Imagen
[Análisis]
Este es un problema de prueba de independencia de chi-cuadrado (χ2) para una tabla de contingencia 2×2. Necesitamos:
Probar la independencia entre las variables categóricas "Sexo" y "Intención de vacaciones fuera de la provincia"
Si las variables están asociadas, calcular el coeficiente de asociación (C de Pearson o V de Cramér)
[Solución]
Paso 1: Organizar los datos observados
La tabla de contingencia observada es:
SI
NO
Total
HOMBRES
80
35
115
MUJERES
85
0
85
Total
165
35
200
Paso 2: Calcular las frecuencias esperadas bajo independencia
La fórmula para las frecuencias esperadas es: eij=total general(total fila i)×(total columna j)
Paso 4: Determinar los grados de libertad y el valor crítico
gl=(r−1)(c−1)=(2−1)(2−1)=1×1=1
Para α=0.05 y gl=1, el valor crítico es: χ0.05,12=3.841
Paso 5: Decisión del test de hipótesis
Hipótesis nula H0: Las variables son independientes (no hay asociación)
Hipótesis alternativa H1: Las variables están asociadas
Como χcalculado2=31.36>χcrıˊtico2=3.841, rechazamos H0.
Conclusión: Existe evidencia estadísticamente significativa para afirmar que hay una asociación entre el sexo y la intención de pasar vacaciones fuera de la provincia.
Paso 6: Calcular el coeficiente de asociación
Dado que las variables están asociadas, calculamos el coeficiente de contingencia de Pearson (C):
También podemos calcular el coeficiente V de Cramér:
V=n⋅min(r−1,c−1)χ2=200×131.36=0.1568=0.396
[Answer]
Resultado de la prueba de independencia:
El estadístico chi-cuadrado calculado es χ2=31.36 con gl=1
Como χ2=31.36>3.841 (valor crítico al 5%), rechazamos la hipótesis de independencia. Existe una asociación estadísticamente significativa entre el sexo y la intención de pasar vacaciones fuera de la provincia.
Coeficiente de asociación:
Coeficiente de contingencia de Pearson: C=0.368
V de Cramér: V=0.396
Ambos coeficientes indican una asociación moderada entre las variables. El hecho de que ninguna mujer haya respondido "NO" (0 observaciones) sugiere una fuerte asociación: las mujeres entrevistadas tienen mayor intención de viajar fuera de la provincia que los hombres.
Resuelve problemas de matemáticas fácilmente paso a paso con explicaciones detalladas. Sube una foto de tu pregunta de matemáticas o escríbela y obtén soluciones instantáneas y claras. Perfecto para estudiantes y cualquier persona que necesite ayuda matemática rápida y precisa.
Resuelve problemas de contabilidad paso a paso con explicaciones claras. Sube una foto de tu pregunta de contabilidad o escríbela y obtén soluciones instantáneas y precisas. Ideal para estudiantes y profesionales que necesitan ayuda con conceptos, cálculos y asientos contables.
Resuelve problemas de economía paso a paso con explicaciones claras. Sube una foto de tu pregunta de economía o escríbela y obtén soluciones instantáneas y precisas. Ideal para estudiantes y profesionales que necesitan ayuda con microeconomía, macroeconomía, gráficos y cálculos.
Resuelve problemas de física paso a paso con explicaciones claras. Sube una foto de tu pregunta de física o escríbela, y obtén soluciones instantáneas y precisas. Ideal para estudiantes y profesionales que trabajan con mecánica, electricidad, ondas y más.
Resuelve problemas de geometría paso a paso con explicaciones claras. Sube una foto de tu pregunta de geometría o escríbela, y obtén soluciones instantáneas y precisas. Ideal para ángulos, triángulos, círculos, geometría analítica y demostraciones.
Responde preguntas de historia con explicaciones claras y estructuradas. Sube una foto de tu pregunta de historia o escríbela, y obtén respuestas precisas con fechas clave, eventos y contexto.
Resuelve preguntas de biología con explicaciones claras y paso a paso. Sube una foto de tu pregunta de biología o escríbela, y obtén respuestas precisas sobre biología celular, genética, fisiología y más.